Hi there,
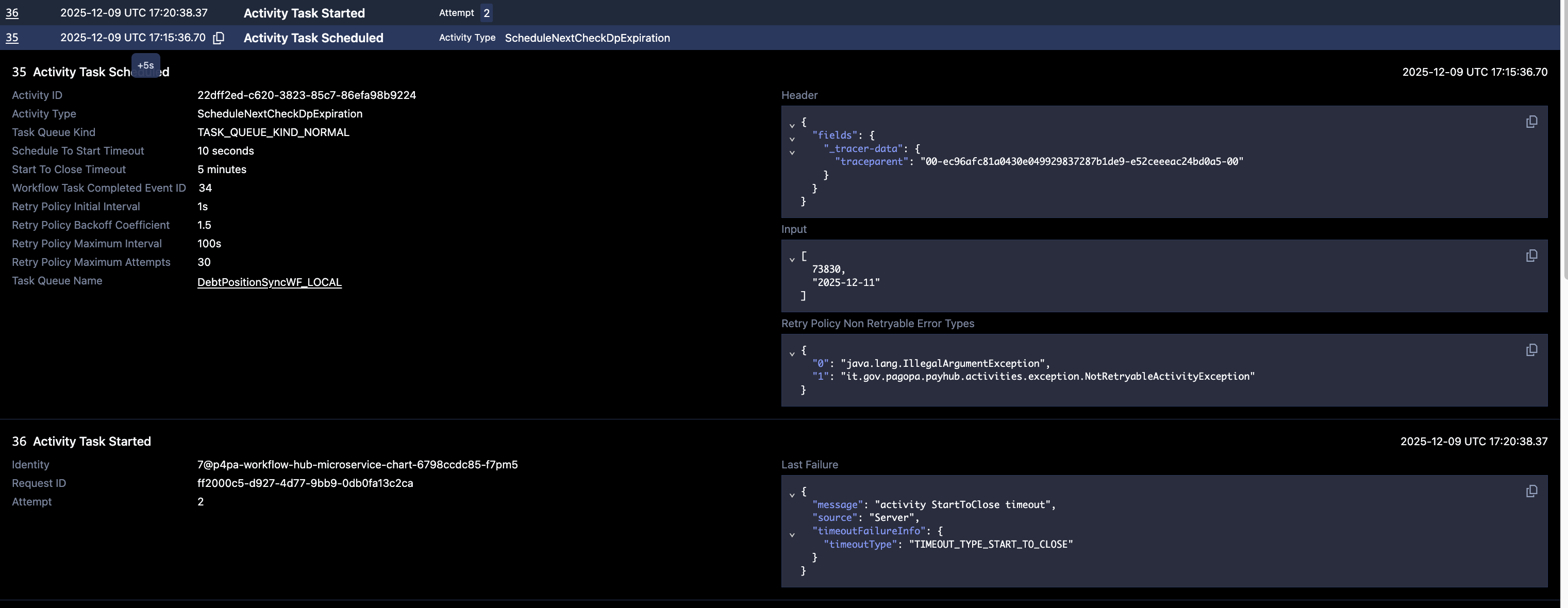
when starting a bunch of workflows in a short timeframe we notice that some activities (at random different activities) are stuck and not processing anything until they are running into their start-to-close timeout and are being retried.
I was able to pinpoint a log error message by temporal-history (version 1.23.1) matching exactly the stuck activity of a given workflow stating
Fail to process task
and extras
{
“component”: “transfer-queue-processor”,
“error”: “context deadline exceeded”,
“lifecycle”: “Processing failed”,
“level”: “error”,
}
Including this stack trace:
go.temporal.io/server/common/log.(*zapLogger).Error
/home/runner/work/docker-builds/docker-builds/temporal/common/log/zap_logger.go:156
go.temporal.io/server/common/log.(*lazyLogger).Error
/home/runner/work/docker-builds/docker-builds/temporal/common/log/lazy_logger.go:68
go.temporal.io/server/service/history/queues.(*executableImpl).HandleErr
/home/runner/work/docker-builds/docker-builds/temporal/service/history/queues/executable.go:421
go.temporal.io/server/common/tasks.(*FIFOScheduler[...]).executeTask.func1
/home/runner/work/docker-builds/docker-builds/temporal/common/tasks/fifo_scheduler.go:224
go.temporal.io/server/common/backoff.ThrottleRetry.func1
/home/runner/work/docker-builds/docker-builds/temporal/common/backoff/retry.go:117
go.temporal.io/server/common/backoff.ThrottleRetryContext
/home/runner/work/docker-builds/docker-builds/temporal/common/backoff/retry.go:143
go.temporal.io/server/common/backoff.ThrottleRetry
/home/runner/work/docker-builds/docker-builds/temporal/common/backoff/retry.go:118
go.temporal.io/server/common/tasks.(*FIFOScheduler[...]).executeTask
/home/runner/work/docker-builds/docker-builds/temporal/common/tasks/fifo_scheduler.go:233
go.temporal.io/server/common/tasks.(*FIFOScheduler[...]).processTask
/home/runner/work/docker-builds/docker-builds/temporal/common/tasks/fifo_scheduler.go:211
From this line: temporal/common/tasks/fifo_scheduler.go at v1.23.1 · temporalio/temporal · GitHub
Can you help me understand what is failing here and how we can prevent this from affecting an activity being stuck until the start-to-close timeout is actually hit?