Hello, i got an issue where its intermittent, sometimes when there is a parent workflow tried to initiate a child workflow it got stuck for some reason
and something in common for every stuck CWF is the event of the CWF is only getting initiated but no event for executed, while in success execution i can see Cwf getting initiated and getting started
any suggestion how i trace the issue ? or how i can terminate cwf when its note getting executed yet ? since its stuck and cannot reset since the cwf still running
I dont think we have any specific type of async replication.
What do you mean by reinstall the cluster? do we need to drop/truncate certain table or how?
and also does reinstall the cluster, will impact the existing workflow that running?
I’m not sure if reinstalling will help if your DB loses records. Usually, this happens when some sort of replication is used, and it is not fully consistent. As I know nothing about your specific setup it is hard to give any recommendation.
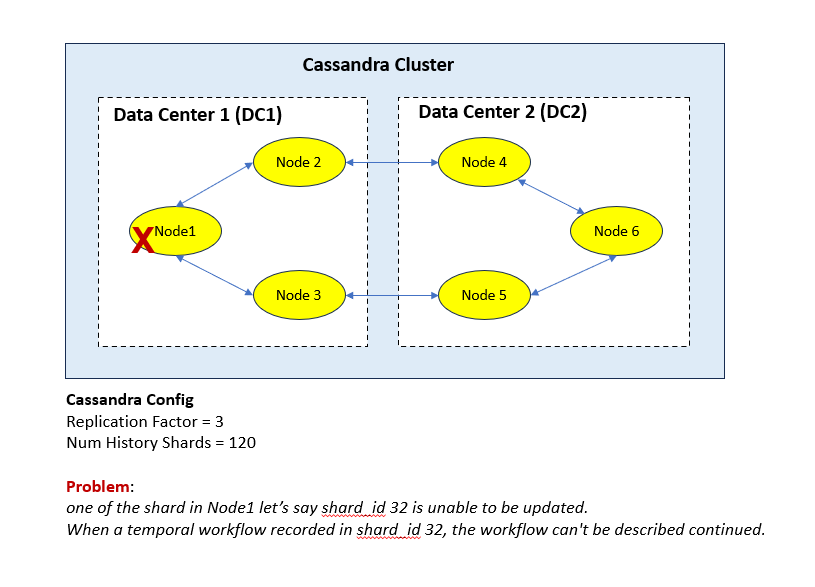
we already try temporal tctl command “tctl admin shard close_shard”, but it seems doesnt solve the problem.
we already try to exec cassandra command such as nodetool removenode, cleanup, repair. but the problem is still there.
we capture log from temporal history service:
{“level”:“error”,“ts”:“2024-02-02T02:54:57.744Z”,“msg”:“Persistent store operation failure”,“service”:“history”,“shard-id”:32,“address”:“10.59.68.74:7234”,“shard-item”:“0xc00277ea00”,“store-operation”:“update-shard”,“error”:“Failed to update shard. previous_range_id: 30415, columns: (range_id=30414)”,“shard-range-id”:30416,“previous-shard-range-id”:30415,“logging-call-at”:“context_impl.go:732”}
If lets say i setup a new cluster, is there any way we migrate the existing data from existing to the new cluster? and not impacting the current workflow process/state
Hi @maxim , @tihomir ,
I try to execute tctl command to describe shard_id but there is one shard_id that the update_time is not updated like the other shard.
tctl admin shard describe
do you know why the shard_id is not updated?
if i want to block transaction to come to this shard, can i use command tctl admin shard close_shard ? this mean the new transaction after i close the shard should be directed to other shard.
or is there any other way for me to isolate that shard