I’m currently implementing workflow which will act like a queue. It will receive tasks via signals and then run child workflows. To omit long history I’m using continue-as-new temporal feature.
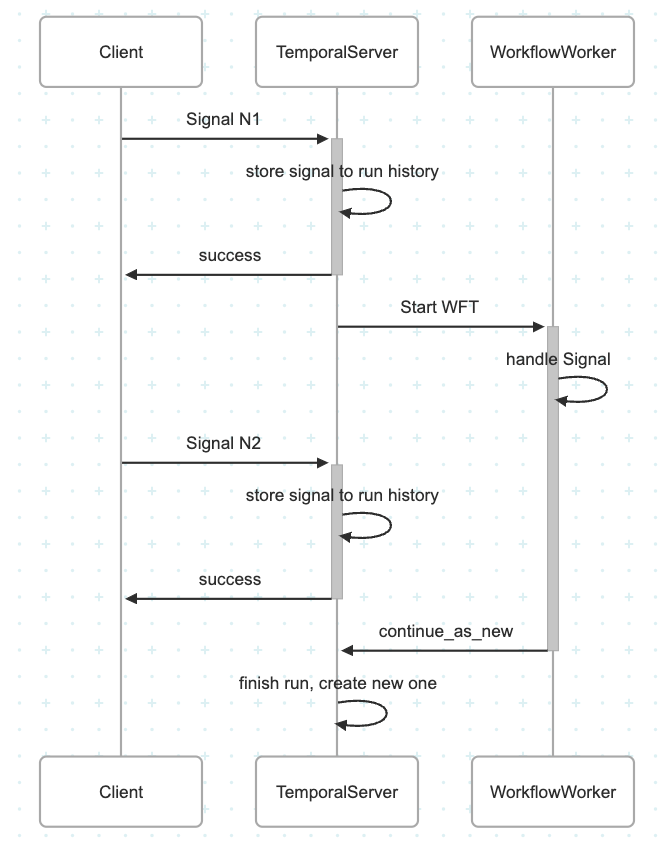
Now I investigate how signals are passed between current run and next one spawned by continue_as_new method. Other languages SDK documentations tells that we need to drain all signals and pass them to next run via parameters. But in my understanding there’s a chance that some signals will be missed.
Here’s a test workflow I wrote to explore this:
class TestWorkflowJob(BaseModel):
sequence: int
class TestWorkflowParams(BaseModel):
queue: list[TestWorkflowJob] = []
@workflow.defn
class TestWorkflow:
def __init__(self):
self._queue = []
self._total_created = 0
@workflow.signal
async def enqueue(self, params: TestWorkflowJob) -> None:
self._queue.append(params)
async def init(self, params: TestWorkflowParams) -> None:
self._queue = params.buffer.copy()
@workflow.run
async def run(self, _: TestWorkflowParams):
print("Starting workflow", workflow.info().run_id)
await workflow.sleep(timedelta(seconds=1))
# This is a workaround to "pause a workflow" to check race condition
i = float(0)
for _ in range(10000000):
i = math.sin(float(i * 2))
print(f"Continuing as new {int(i*1000) & 1} {workflow.info().run_id}")
await workflow.continue_as_new(
TestWorkflowParams(
queue=self._queue,
),
)
I also wrote a script that sends a signal every 0.1 seconds to test this.
My concern is that after the last yield (in this case, the sleep), but before continue_as_new is called, new signals could be received and get lost as there’s no any other yield.
But in practice, everything seems to work fine — I’m not seeing any lost signals.
Can someone explain why this works? Is there some internal guarantee in the Temporal runtime that prevents signal loss between runs? Or are signals maybe attached to the workflow as a whole, not to a specific run?
You’re not going to miss signals scoped to the workflow id. They’ll either be delivered to the current workflow or to the continue-as-new workflow.
But, if you start doing some work in response to a signal (i.e., there’s something you’ve called await on), you’ll want to finish that work before calling continue_as_new so that you don’t lose that context. That is, if you call continue_as_new while some other code is waiting on an await, the workflow code after the await will never be executed.
Meanwhile, while you’re waiting for your current work to finish, you might get more signals! That’s why you start queuing signals, you don’t want to keep starting new work and then never have a chance to call continue_as_new without losing work in progress.
Your “pause a workflow” loop isn’t going to do anything because workflows are single-threaded.
I understand that workflows executions are single threaded, but temporal server is not. Signals do not sends directly to worker, but to temporal server and then temporal server schedules a task to workflow worker.
“pause a workflow” is to give possibility to Signal 2 to be stored on TemporalServer between workflow.sleep and workflow.continue_as_new.
If you workflow worker crashed during processing in one of your signal handlers, the signal wouldn’t be lost because the Temporal Service atomically saves the workflow step and the signal having been delivered together. When the workflow is replayed the signal is still available to be delivered because the workflow step that would have consumed the signal never completed. I don’t know the details but I suspect something similar would happen after you call continue_as_new; the signal wouldn’t be consumed by the first workflow because it never executed the code to process the signal.
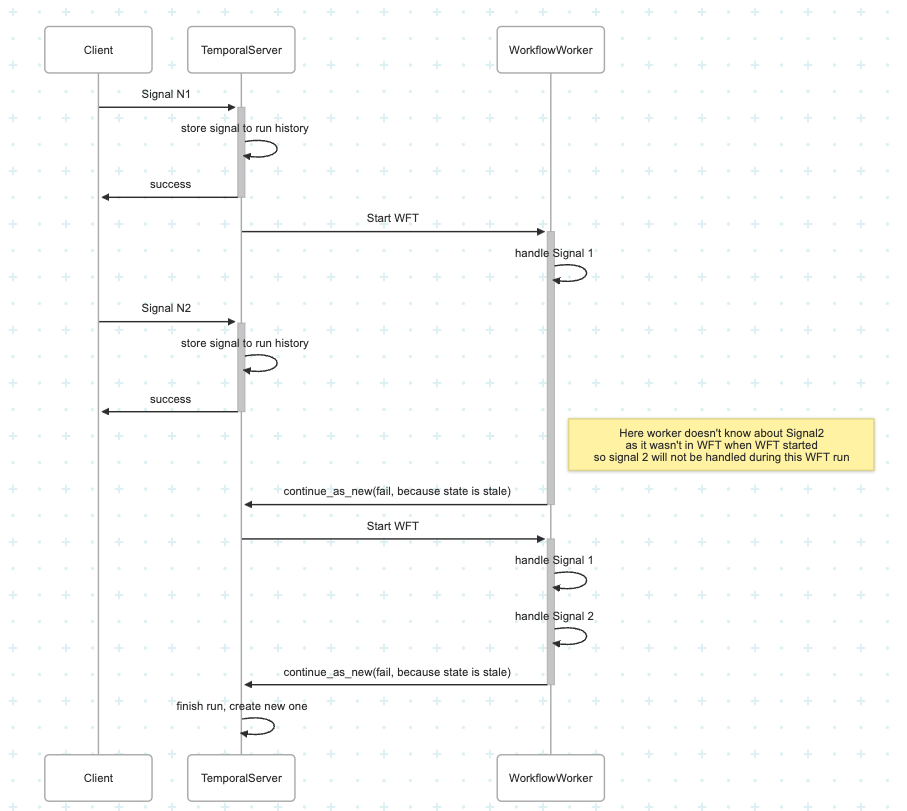
Actually my further investigation shows that continue_as_new method just finishes with error if some other signal were received between sleep and continue_as_new, then workflow server schedules another WFT to worker which will now catch new signal. But maybe my considerations are wrong.
PS. Yep, it looks like it’s true, there’s a special error code that is returned when workflow tries to finish with unhandled signals. Errors | Temporal Platform Documentation